According to the principles of Behavior Driven Development (BDD), we discuss examples and write them down as Gherkin scenarios. These scenarios can be turned into automated tests by BDD tools like Cucumber or SpecFlow, so that the implementation can be “driven” by them. So it is like TDD. But if it is like TDD, there arises the question whether we also need unit tests and classic unit-level-TDD as well in addition to our scenarios. This is a complex question and it is not easy to give a simple constructive answer for it. In this post, I am taking a concrete example to show how this can be imagined.
I have recently fixed a bug in SpecFlow and realized that the story of this fix might be a good case study to illustrate the challenges related to finding the right balance between scenarios and unit tests. So let me first introduce the bug and the circumstances of fixing it. After that, we will have a look what the BDD guidelines would dictate and finally see how this can be adapted to our concrete example.
The feature
The bug was related to a feature that is not commonly used in SpecFlow: when writing step definitions, you don’t necessarily have to annotate the method with a regular expression. If the method is named according to some simple rules, the match can be calculated automatically by SpecFlow. So for example, to be able to match the “When I do something” step, you can write a step definition, like
[When]
public void When_I_do_something()
{ … }
You can also use this for parametrized step definitions, in this case the parameter name has to be combined into the method name in ALL CAPS, like
[When]
public void When_WHO_does_something(string who)
{ … }
This step definition will match steps like “When Joe does something” or “When ‘Jill’ does something”.
This looks like a nice feature that makes the step definitions much clearer in most of the cases, in the remaining cases you can still switch back to regex, as these definition styles can be mixed even within the same step definition class. The feature is not only nice, but – as you can see – it is relatively easy to explain to someone. The two examples above probably give you a good understanding what this is all about.
So when I implemented the first version of the feature 5 years ago, I started the development by describing these examples as SpecFlow Scenarios, as you can find it on GitHub still. The feature supports a couple more options, which are not so important for our case study, but the scenarios for these two examples were described as
The implementation
The original implementation was purely driven by the scenarios. There were no additional unit tests. The core logic of the implementation is in a class called StepDefinitionRegexCalculator and it basically calculates a regular expression based on the method name. The calculation (at least logically) is done in three steps. (The examples are simplified for an easier understanding.)
- First, it removes the keyword prefix (like
When_). This turns the method nameWhen_WHO_does_somethingintoWHO_does_something. - Then it tries to find the parameter markers (like
WHOin our example) and substitutes it with a regex group that will mark the parameter in the step text. As a result, we would have something like(.*)_does_something. - Finally, it takes the method name parts between the parameters and replaces
_(underscore) with something that matches the whitespaces between the words, so we would get something like(.*) does something, which is a proper regex to match our steps.
The bug
The devil is in the details, as we know. This simple-looking feature has to work under many different circumstances. We have already mentioned that the parameters might be surrounded by quotes or apostrophes, but it also has to handle steps where there is some extra punctuation in the step text, like “Given John, the administrator does something” and it also has to handle special parameters that include currency symbols (“Then the sum should be £100”). There was a bug recorded earlier, which was related to negative numbers passed in as parameters, like in the step “Given I enter -100 into the calculator”. If you put this in contrast with the step “Given there is a well-known issue”, you can see that this example is a special corner case, showing that the “-” can be included both as punctuation and as a part of the parameter.
But my bug was even worse than these. Let’s say you have a step text parameter, surrounded by quotes/apostrophes, and this parameter stands at the end of the step text, like in step “When the user searches for ‘SpecFlow'”. If you declare a step definition method as void When_the_user_searches_for_Q(string q), the parameter that is passed in to this method will contain the leading apostrophe, so the string “SpecFlow'” is passed in. Notice the apostrophe before the closing quote. It is hard to see it, right?
Who would think that an implementation, which works for quoted parameters, will behave differently if that parameter is at the end of the step text? And if this is the case, how many other combinations might exist where the implementation is wrong? This bug shows that the system can misbehave in much more different ways than you would think. No wonder that no one really wanted to fix this bug and in general to touch this codebase for a long, long time. Any change might cause additional side-effects.
The testing pyramid
The testing pyramid concept was described by Mike Cohn in his book Succeeding with Agile. It gives us a guidance on the right balance of the different kind of tests. You might want to have a lot of unit tests that can run quickly and are relatively cheap to implement and maintain. You might want to have less higher level tests that should not concentrate on each individual decision your units make. Instead of these, these tests should focus on the question whether these units can work well together and properly interact with external interfaces, including the user interface.
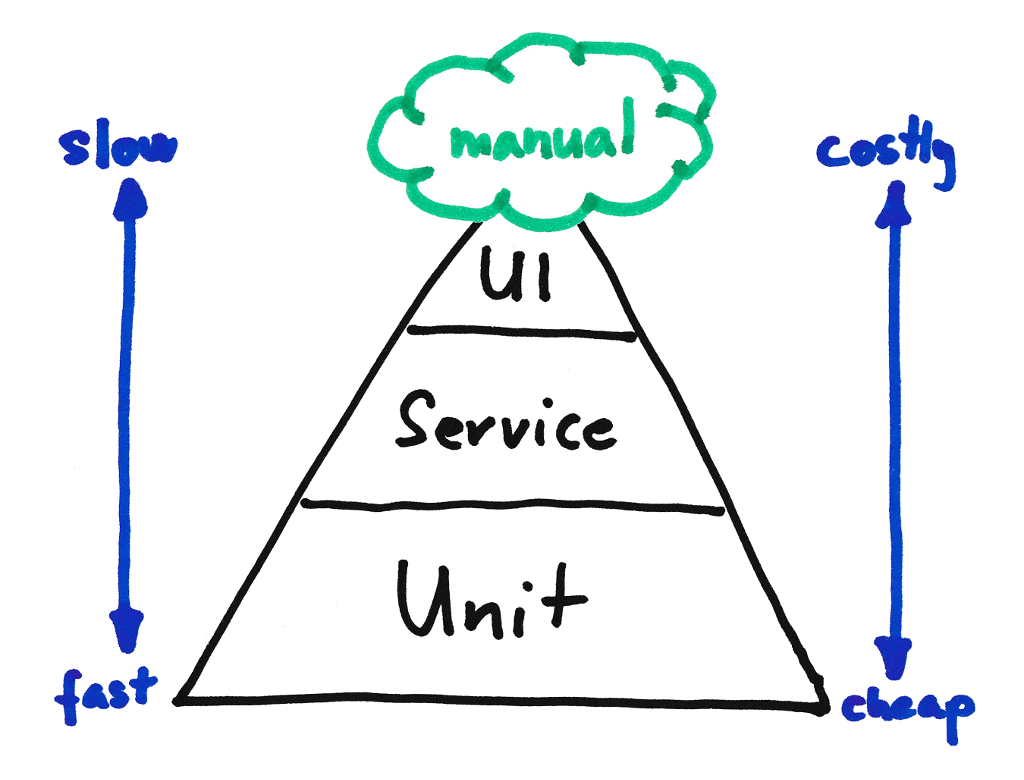 But where do BDD scenarios come into the picture? Should the scenarios test your application through the user interface and fill up the lower levels of the pyramid with technical unit or integration tests? Many teams start their test strategy this way, but this usually leads to a distorted “pyramid”, more like a testing ice-cream that contains a lot of slow and costly UI tests and there are only a few tests in the lower levels. As the feedback you can get from the tests is very slow (you might need to wait for hours), people gradually ignore these tests and finally automated tests will only be an overhead that hinders you to implement new features.
But where do BDD scenarios come into the picture? Should the scenarios test your application through the user interface and fill up the lower levels of the pyramid with technical unit or integration tests? Many teams start their test strategy this way, but this usually leads to a distorted “pyramid”, more like a testing ice-cream that contains a lot of slow and costly UI tests and there are only a few tests in the lower levels. As the feedback you can get from the tests is very slow (you might need to wait for hours), people gradually ignore these tests and finally automated tests will only be an overhead that hinders you to implement new features.
At the time when we discuss the examples (scenarios) of the features, we don’t want to limit ourselves to discussing details regarding the interaction of the units and the external interfaces. In fact, at that time we don’t even know what our units will be. We try to understand the requirements and in order to understand them, we might need to discuss little details and high level workflows as well. I guess you know it by now: automated scenarios cannot be mapped to a specific level of the testing pyramid. Depending on the scenario, you might want to automate it as unit, integration or UI test.
Does this mean that we have to implement every automated test as a SpecFlow scenario? You could do this of course, but usually writing down the tests in a business readable form has the real advantage if the problem you address with the test is interesting for the business. Being interesting for the business means that you need to study it for the better understanding of the problem or you want to get feedback from the business whether the test really describes the expected behavior. So those business-interesting tests will be automated through Gherkin scenarios and everything else in the pyramid is probably implemented as technical test. Visualizing this distinction on the testing pyramid makes our pyramid looking more like a testing iceberg, where the business-interesting tests are the ones that are above the “sea-level”.
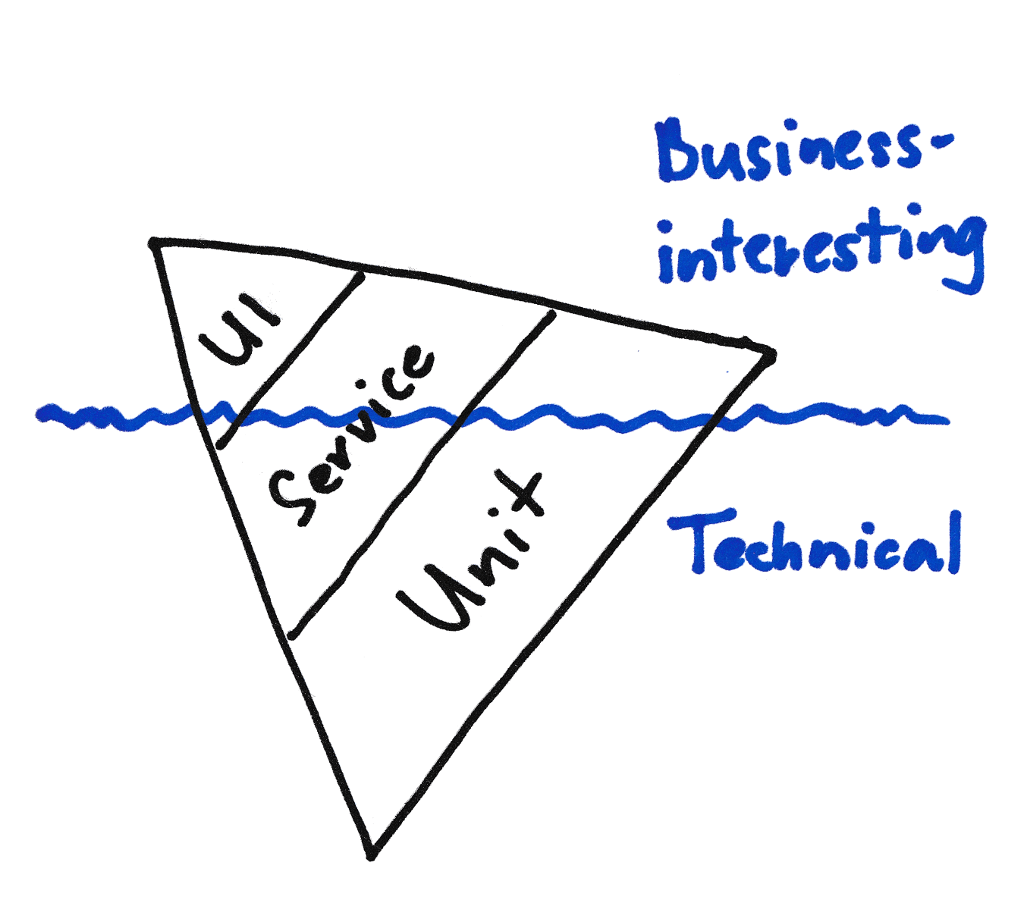
We miss the undersea tests!
Let’s get back to our SpecFlow feature and the bug and sort out the examples we have seen so far.
| problem | classification |
|---|---|
|
Works with underscore-named methods |
business-interesting |
|
Supports multiple whitespace characters and tabs (2 tests) |
undersea |
|
Supports punctuation |
business-interesting |
|
Supports ,.;!?-: as punctuation (~10 tests) |
undersea |
|
Can mix whitespace and punctuation between words (3 tests) |
undersea |
|
Can use PARAM markers in the method name |
business-interesting |
|
Can use parameters in the front/middle/end of step text (3 tests) |
undersea |
|
Can pass in -100, £100 as parameters (2 tests) |
undersea |
Seeing this table and the bugs that were found, the problem is becoming clear! We have missed the “undersea” tests: those simple unit tests that can verify all variations and corner cases much more efficiently than tests implemented as Gherkin scenarios. Just imagine how boring it would be to read different scenarios that use parameters in the front/middle/end of step text.
But how would you know which unit tests to add? In the concrete case, how would you come to the idea to test the parameter placing in the front/middle/end of step text? Without releasing it and letting the users find the bug, of course. It is easy! Because at the time we write the unit tests, together with the unit, you are also aware of the implementation structure and logic. In fact you don’t even write all the unit tests upfront, but just add more and more as you see how the implementation is taking shape. In our case, we have chosen to split the method name by the parameter markers and then processed the texts “in between” these. When you implement the logic this way, you will need to handle the case when the parameter marker is at the end of the method name (ie. there is no “in-between” part after that). So before you add this special logic, you need to add a unit test first:
If we had chosen another algorithm for the implementation, we would have ended up having different unit tests. But this is all fine, because with a different algorithm you would also have different potential misbehavior that we would like to avoid.
What sounded mysterious and frightening is clear and logical now. The scenarios ensured the understanding and the unit tests ensured the code quality.
How did our story end?
We had the bug and it became clear that the root cause was that the person who implemented this feature (happens to me :)) did not take care of the right balance of the scenarios and the unit tests.
As I did not want to reimplement the entire feature from scratch, I finally decided to implement unit tests based on the knowledge I had about the requirements and the solution. Using the combinatoric testing features of NUnit, it was pretty easy to test many different combinations.
I had probably more tests (70+) this way than what would have been added if I had used TDD. But this is not necessarily a problem, because each test can be executed in less than a millisecond, so even all 70+ tests run faster than a single integration test. My primary goal was to ensure a coverage for the current behavior (including the bugs), so that I can make changes without worrying about the side-effects. My tests were serving as a temporary infrastructure that supports further development. I call this technique scaffolding, and it is very useful for working with legacy applications. But this is another post…